
3.2. Timer interrupts
1. Introduction
In many applications with signal processing involved, you want the computation loop to be triggered at regular time intervals providing a stable sampling period. A common way to do this is to implement a timebase with a timer that fires an interrupt every update event.
2. Using the timer to generate periodic interrupts
2.1. Setting up the peripheral
In bsp.c, adjust the TIM6 timebase settings in order to achieve a 200ms period between update events, and enable update interrupts:
/*
* BSP_TIMER_Timebase_Init()
* TIM6 at 48MHz
* Prescaler = 48000 -> Counting period = 1ms
* Auto-reload = 200 -> Update period = 200ms
*/
void BSP_TIMER_Timebase_Init()
{
// Enable TIM6 clock
RCC->APB1ENR |= RCC_APB1ENR_TIM6EN;
// Reset TIM6 configuration
TIM6->CR1 = 0x0000;
TIM6->CR2 = 0x0000;
// Set TIM6 prescaler
// Fck = 48MHz -> /48000 = 1kHz counting frequency
TIM6->PSC = (uint16_t) 48000 -1;
// Set TIM6 auto-reload register for 200ms
TIM6->ARR = (uint16_t) 200 -1;
// Enable auto-reload preload
TIM6->CR1 |= TIM_CR1_ARPE;
// Enable Interrupt upon Update Event
TIM6->DIER |= TIM_DIER_UIE;
// Start TIM6 counter
TIM6->CR1 |= TIM_CR1_CEN;
}
Then, set the priority and enable TIM6 interrupts in the BSP_NVIC_Init() function:
/*
* BSP_NVIC_Init()
* Setup NVIC controller for desired interrupts
*/
void BSP_NVIC_Init()
{
// Set maximum priority for EXTI line 4 to 15 interrupts
NVIC_SetPriority(EXTI4_15_IRQn, 0);
// Enable EXTI line 4 to 15 (user button on line 13) interrupts
NVIC_EnableIRQ(EXTI4_15_IRQn);
// Set priority level 1 for TIM6 interrupt
NVIC_SetPriority(TIM6_DAC_IRQn, 1);
// Enable TIM6 interrupts
NVIC_EnableIRQ(TIM6_DAC_IRQn);
}
At this point, we wrote all the required code to have an interrupt signal out of TIM6 peripheral every 200ms, that the NVIC controller will propagate.
2.2. Writing the interrupt handler (ISR)
As said before, when the interrupt signal is propagated by the NVIC controller, the program execution will automatically branch to a specific code memory address. Looking in the assembler file startup_stm32f0xx.S will tell you that the function name corresponding to the TIM6 interrupt handler (or ISR) is: TIM6_DAC_IRQHandler(). If you wonder why the name includes ‘DAC’, the reason is that TIM6 has a specific feature associated with the DAC that other timers have not. We’re not using it so far, so you may just consider TIM6 as a regular basic timer.
Let us write something simple in stm32f0xx_it.c as TIM6 Interrupt Service Routine (ISR):
/*
* This function handles TIM6 interrupts
*/
extern uint8_t timebase_irq;
void TIM6_DAC_IRQHandler()
{
// Test for TIM6 update pending interrupt
if ((TIM6->SR & TIM_SR_UIF) == TIM_SR_UIF)
{
// Clear pending interrupt flag
TIM6->SR &= ~TIM_SR_UIF;
// Do what you need
timebase_irq = 1;
}
}
Timers can be used to fire interrupts in many situations. Therefore, and it should be an automatic practice each time you write an interrupt handler, we start by testing which event lead us to the interrupt service routine. Because we only turned on the interrupt based on “update” event, there should be no other reason to be there… but still, it has to be done by verifying that the UIF flag is set, and then clear it to re-enable next interrupt signal
Remember that ISR must be short. Here we only set to ‘1’ a global variable timebase_irq. This variable will be tested into the main() function.
2.3. The main() function
The main loop now keeps polling global variables to test whether interrupts occurred. Based on the value of these variables, actions are performed:
// Global variables
uint8_t button_irq = 0;
uint8_t timebase_irq = 0;
// Main function
int main()
{
// Configure System Clock
SystemClock_Config();
// Initialize Button pin
BSP_PB_Init();
// Initialize Console
BSP_Console_Init();
my_printf("Console Ready!\r\n");
// Initialize timebase
BSP_TIMER_Timebase_Init();
// Initialize NVIC
BSP_NVIC_Init();
// Main loop
while(1)
{
// Process button upon interrupt
if (button_irq == 1)
{
my_printf("#");
button_irq = 0;
}
// Process main task upon timebase interrupt
if (timebase_irq == 1)
{
my_printf(".");
timebase_irq = 0;
}
}
}
Build and flash the project into the target. Open the console and see if you have a ‘.’ printing every 200ms.
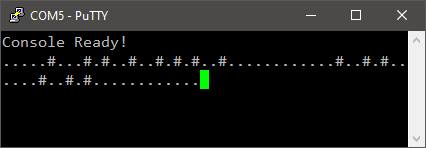
The system is now very responsive to the push-button pressure because is it spending most of the time looping through the test of the two global variables waiting for an event to process. In the same time, the main task is reliably processed every 200ms.
 | - - |
3. Summary
In many situations, the MCU will be asked to process data at regular time intervals. Using delays in loops must be avoided because a delay is something that keeps the MCU busy (counting). Using timers together with interrupt must be your first choice. The setup shown in this tutorial can be used as a basic configuration for many applications.